Gemma4 on Oracle Free Tier is surprisingly usable

I'm currently testing the new open source AI models by Google. Up until now, although I was aware of open source AI, I cannot say I was particularly interested in self-hosting it, due to limited compute resources and high electricity prices. But maybe Oracle might be my saviour here. I tried the Gemma4 models because of the hype around these models which even I would notice.
I won't go into too much detail on the Oracle free instances, but in short, the offer comes with 200GB of space, a 4-core ARM CPU and 24GB of memory. Because free instances are consistently out of stock, you have to upgrade to the pay-as-you-go model. This ensures you get an instance, but also has a bit of a risk to lose a lot of money, because of a misconfiguration. As a tip: because the overview of Oracle is rather confusing, I used Gemini 3 Pro a lot, which was super helpful. Apart of 2 settings, it was very well informed in what I have to click and what not.
I tested all Gemma4 variants on Ollama, which are e2b, e4b, 26b and 32b. The e4b variant only needs 10GB of memory, the e2b 7.2GB. The 26b model is the largest Gemma4 model on Ollama where I would say it's reasonably usable. When fully loaded it needs around 18GB of memory. On my instance with docker and this blog running, this still leaves me with 3.3GB of memory, which for my blog should suffice more than enough. While generating, the CPU consistently sits at 100%.
The 31b model was to large in my test. Because I use the instance to run this blog, I have to keep memory constraints in mind. I could imagine that with some optimisations particularly on the llama.cpp level, using this model could be feasible on the instance.
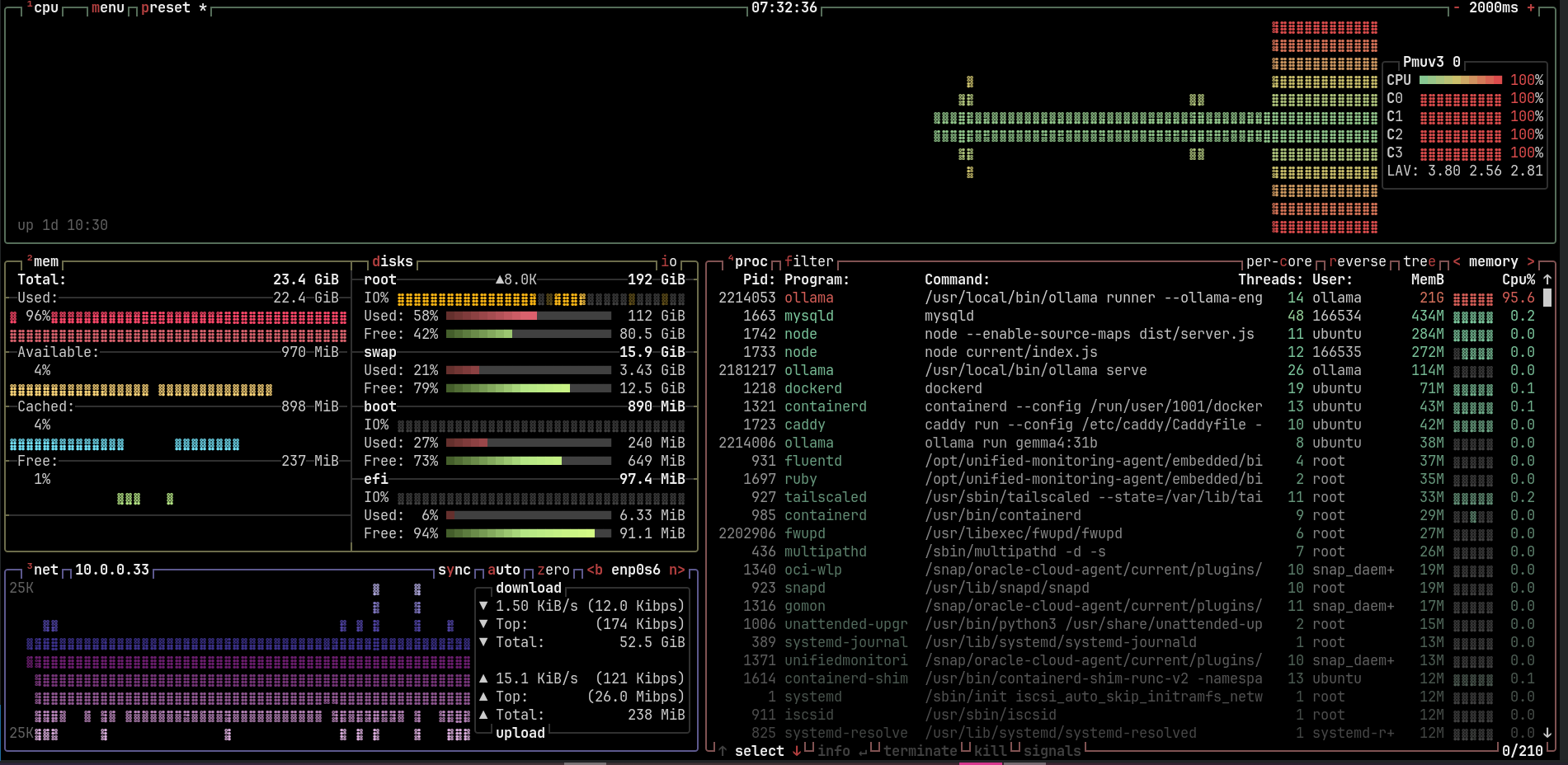
Interestingly, all models seem to show very similar token speeds. In my early testing the main time differences resulted out of different thinking verbosities. With particularly the 26b taking the longest time. All models produced an output speed of around 4-8tokens/second. I haven't looked deeper into it, but even as a non-self-hoster of AI I came across some debates on Ollama. Apparently, using llama.cpp over Ollama can lead to a 180% speed improvement, according to this article: Link.
While the speeds of the models, even if they get a twice as fast, aren't super impressive, it's absolutely exciting to being able to host AI 100% privately for free. People are very afraid of price increases, but than this is possible in 2026?? I mean, this is so incredibly accessible to everyone, it's ridiculous.
I can't say a lot about the intelligence of the models as I hadn't had time to test it, but people on Reddit seem to be very happy with it. My own experiments with OSS AI models were a while back. Back then they were very much unusable. Compared to then they seem to have make a big jump. I tried proof reading this text with the models and the results are absolutely fine. With this use case it's more of a time problem, because in the time the model generates an answer I have already rewritten large chunks of the text myself.